One of the most important factors affecting
database
performance is buffer pool performance. The way in which buffer
pools
work need to be understood to leverage and tune buffers
Buffering will be dealt in several parts.
Let us see the basics of buffering and buffer pool hits.
DB2 Engine is made of three logical blocks. Relational Data Services
(RDS),
Data Manager (DM) and Buffer Manager (BM)
to simplify things, the details of RDS and DM can be summarized as
follows. When presented with an SQL the RDS determines the access path
and asks
the data manager to get some rows from the table. Let us assume that
the RDS is
looking for exactly one row from a table. The data manager for its part
determines what database the row belongs to (DBID), what table space
the row
belongs to (PSID) and what page holds that row (Page). This information
is passed
on to the Buffer Manager.
Now the Buffer Manager takes over and its duty is to get that page into
a
buffer and inform the data manager that the page it requested is
available in
the buffer.
A very simple overview of the process is illustrated by the figure
below.
Step1. Data Manager asks the Buffer Manager for Page "X"
Step2. Buffer Manager Searches through the buffers of the buffer pool
that is
allocated to that object to see if that page is available.
Step3. If that page is available (Green page) BM returns the value to
the DM
and it is a buffer pool hit.
Step4. If that page is not available in any of the buffer pages
(Red page
signifying end of search)
then the page has to be read from disk into a free buffer page (Yellow
page)
and the value is returned to the DM. This constitutes a buffer pool
miss.

To understand the mechanism of buffer pool
searching,
Let us assume a table space TS1 that has 50 pages. Let us
further
assume that TS1 is allocated to buffer pool BPN whose size is 10000
pages. If
the DM asks for a page "nnnn" from TS1 then the BM has to some
how determine if this page is in the buffer. It will be inefficient for
the BM to
scan through all the 10000 pages of BPN to check for page "nnnn"
of a TS1 that has just 50 pages. In other words it would be
better
to scan the table space than the buffer for that page.
To avoid this problem, DB2 buffering strategy uses a concept called
Address
Hashing.
Any Hashing process (program) takes an input
value and transforms
it into a totally random number which is fixed for that input value.
Assume that there is a hashing algorithm that takes people's names as
input and
generates a totally random 5 digit number.
for example the name "RAMACHANDRAN
SUBRAMANIAN" generates 29065 ( a totally random
number ) and
the name "TAPIO
LAHDENMAKI"
generates 18732 ( an other totally random number )
and
the name "RAUL
GONZALEZ"
generates 58334.
Even though the numbers might be random, if presented with the same
input name
multiple times, the output number will be the same. In other words, if
presented with the name "RAMACHANDRAN SUBRAMANIAN" for the
second time, third time or hundredth time the generated number
will still
be 29065. The same is true for other names too.
Some times it might so happen that two input values (names) generate
the same
hash value (random number).
for example the name "RUSSELL MYERS"
generates 92675 and
"HO CHI MINH" generates the same 92675 then "RUSSELL
MYERS" and "HO CHI MINH" are said to be synonyms of that hash
value.
Each hashing algorithm has certain characteristics such as the
number of
distinct values it can generate, the maximum number of synonyms it can
generate
etc.
Let us see how this applies to DB2 buffering. Remember the problem at
hand is
to avoid scanning through the entire 10000 pages in the buffer.
When the DM asks for a particular page "nnnn", it passes the
DBID, PSID and Page Number to the BM.
BM passes the combined key value of DBID.PSID.Page through a
hashing
algorithm and generates a hash value or hash key.
BM also maintains a hash table. The hash table can be thought of as
having
two columns. First column is the hash value for (DBID.PSID.Page) and
the second
column is a pointer to the data page in the buffer pool
that
produced the hash value.
For example if DBID 100 PSID 80 Page 400 and if the hash
value for
this combination is "6A00C" then the hash table will have one row
with two column values, "6A00C" and "pointer to the data
page that belongs to DBID 100 PSID 80 and Page 400".
How can DB2 pinpoint the location of a given page with the
help of a
random number?
The trick lies in the fact that every time a data page is read from
disk BM
passes the (DBID.PSID.Page Number) of that page through the same
hashing
algorithm and determines the hash key. Now DB2 knows where it has put
the data
page because it just read the data page and wrote it into some
available buffer
and DB2 also knows the hash key because it passed (DBID.PDID.Page
Number)
through the hashing algorithm. DB2 now updates the hash table
with the
relevant information.
So when the BM goes looking for a particular page and if that page
has
been read previously and still is in the buffer, the hash table
will
quickly locate that page.
Now the argument can be made that if there are 10000 pages in the
buffer will
there be 10000 hash table entries. If so what is the advantage of
scanning
through 10000 hash table entries.
This is not the case. The hashing algorithm is designed to have some
optimal
number of synonyms. Say 5. So for 10000 buffers there will be
just 2000
hash table entries. All the distinct (DBID.PSID.Page Number)
combinations
generating the same hash value will be chained together through buffer
page
pointers.
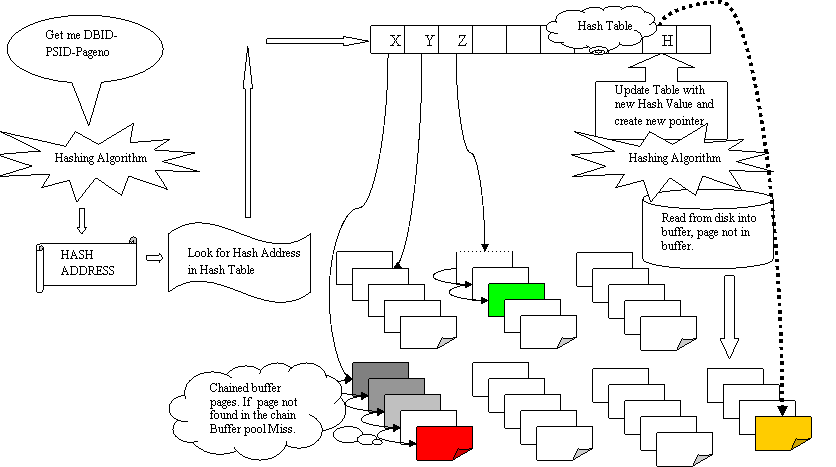
Let us conclude with three scenarios. Follow the
figure
above.
1. Buffer pool Hit. Data Manger asks for (DBIDA.PSIDB.Page Number
N). Buffer
manager passes the key combination through the hashing algorithm
and
produces a hash value Z. BM goes to the hash table and looks up the
hash value
Z and it points to a particular page (The one with the dotted lines).
However
this is not the page DM asked for, but is a synonym for the page
requested. BM
checks the second page that is chained to the first page and finds that
it too
is not what it was looking for. It moves on to the next page in the
chain and
it finds the page it was looking for (in green colour). This is a
buffer pool
hit.
2. Buffer pool Miss. Data Manger asks for (DBIDM.PSIDN.Page Number X).
Buffer
manager passes the key combination through the hashing algorithm
and
produces a hash value X. BM goes to the hash table and looks up the
hash value
X and it points to a particular page (gray colour). However this is
not the
page DM asked for, but is a synonym for the page requested. BM checks
the
second page that is chained to the first page and finds that it too is
not what
it was looking for. It moves on to the next page in the chain, and the
next
page till it reaches the last page in the chain ( in red colour)
without
finding the page it was looking for. This is a buffer pool miss.
3. Buffer pool Miss because no hash table entry found. Data Manger asks
for
(DBIDP.PSIDQ.Page Number R). Buffer manager passes the
key combination
through the hashing algorithm and produces a hash value H. BM goes to
the hash
table and looks for the hash value H. It is unable to find H which
means the
page has not been read into the buffer pool or has been aged out. This
page has
to be read from disk. After reading this page BM passed the
(DBIDP.PSIDQ.Page
Number R) through the same hashing algorithm and derives the hash key.
It finds
a free buffer and writes this page into that buffer and updates the
hash table
with the hash key and the pointer (the curved dotted arrow) to the page
in
which this page was written (in yellow colour).